


Setting Up A Data Stack Without Breaking The Piggy Bank
Here at 173tech we are passionate about driving ROI from data and analytics. One of the biggest blockers to this traditionally was the cost and set-up of infrastructure.
Luckily thanks to cloud and open source providers, this cost has been significantly reduced, to the point where we have been able to set up a complete data stack for only a few hundred dollars a year.
In this article, we’ll give you a real-life example of a cost-effective data stack we’ve built, the tools we used and the general costs involved. (Obviously, prices are always prone to change so be sure to double check before purchasing.)
Key Components
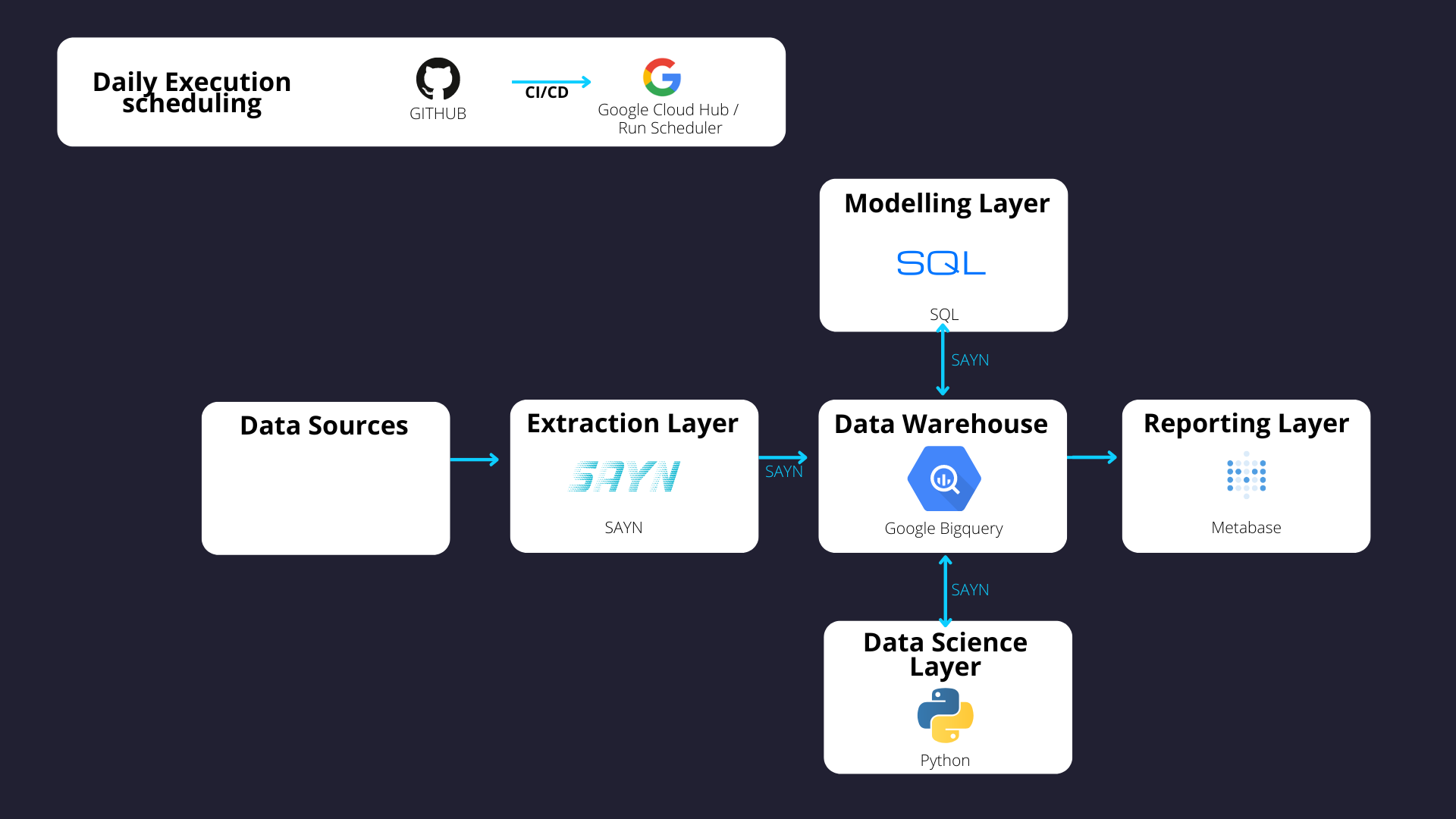
- Data Warehouse: Google BigQuery
- ELT: SAYN
- Deployment: Google Cloud Build / Run / Scheduler
- CI / CD: GitHub Actions
- Visualisation: Metabase
The first time we built this stack, we actually were amazed that you could get such great tooling for such a low monthly bill. Since then, we have implemented it for several clients.
The cost- effectiveness of this stack applies mostly to low data level ecosystems (typically in the tens of gigabytes). It works extremely well for e-commerce and B2B industries which are by nature less data hungry digital businesses, or early stage businesses which will produce less data.
Here are a few benefits of this stack:
- No / little vendor lock-in as the stack mostly uses open source solutions.
- Full control over the business logic and how you report on metrics.
- Serverless approach, making the deployment more secure and resource efficient.
- Extremely cost efficient (obviously!)
The Data Warehouse
The data warehouse is where we centralise all our data. For this, we recommend use Google BigQuery, as it is priced based on the number of terabytes being stored, written (when loading data) and read (when running queries) on the database on a monthly basis.
At the time of writing, the cost of reading a terabyte of data is $5, with the first terabyte being free. The storage costs are $20 per terabyte with the first 10 gigabytes being free.
That means if your data estate is small in volumes you can take advantage of this pricing structure, making your warehousing solution extremely cost effective!
Warehouses like Snowflake and Redshift, as well as traditional databases like PostgresQL, use completely different pricing models which make it impossible to achieve such low prices at any volume.
We recommend that where BigQuery is the warehouse of choice to use Google Cloud Platform (GCP) as the overall ecosystem for the analytics deployment.
Extract Load Transform
For extract, load and transform (ELT) processes, we use our open source framework SAYN. It supports automated database extracts, allows custom extracts through Python tasks and enables automated data transformations in the warehouse. It is a very simple tool to write, orchestrate and run ELT infrastructures and abstracts a lot of data engineering processes (including building a DAG) to make things simpler for end users. As a result SAYN ELTs are extremely simple to deploy and maintain! Because SAYN is open source, it is free to use. The code is hosted on GitHub which can be free or cost a small fee (charged by GitHub) per user depending on the plan you are on. You can add on a data extraction tool (e.g. Stitch) later to scale the number of data sources.
Deployment
For this, we use a serverless deployment which means that the resources to run the code are only up whilst the code is running. As a result, instead of paying for a full time machine, you only pay for a few minutes of execution time on a daily basis. It is also more secure as this means you do not have a machine constantly up and running, so this is one less potential entry point to your infrastructure. For this part of the stack, we use Google Cloud Build, Google Cloud Run and Google Cloud Scheduler – the three combined will run for a few pennies a month given that the overall data processing time is extremely short.
With these tools, we will effectively build a docker image and run containers on a daily basis. You can automate the Cloud Build processes for Continuous Delivery (CD) through the Google Cloud Run interface with a few clicks.
Data Testing & Continuous Integration
GitHub Actions provide a fairly generous amount of free actions time for your CI processes, meaning that your CI can cost you nothing on a monthly basis. GitHub Actions can replace Cloud Build for the CD to centralise all CI / CD processes but is unnecessary if you want to keep your infrastructure light and simple.
Adding Your Visualisation Layer
Your visualisation layer can also be extremely cost efficient, with great tooling! If you want to keep a low monthly bill, then you can use Metabase – an attractive open source reporting solution. If you decide to deploy yourself, you will only pay for the resources your Metabase instance consumes (likely around $25 – $50 a month at initial levels).
Data Engineering & Setup
While the ongoing costs of a data stack can be quite low, depending on your data usage, what about setup and engineering?
The most expensive part of creating a data pipeline for customers is actually in the modelling. Data Modelling transforms the information from your extracted source into a format useful to your business. It applies logic onto the data to help you organise it. The difficult in this is that every business is unique and so too will their business logic. That means that modelling the data is a bespoke task.
We typically recommend that companies focus on their core KPIs, transform that data, feed it into a reporting tool and expand from there. This means you start to get value from data as quickly as possible as opposed to modelling every single piece of information available.
While this will undoubtedly be the most expensive part of any stack, and once completed this stack should be suitable for years to come.
How 173tech Can Help
If you are looking to kick-start your analytics and build a data stack that will scale with your business, why not get in touch with a friendly member of our team?