


How Is Data Activated Today?
In the age of information, data has become the lifeblood of modern businesses. Companies have access to an unprecedented wealth of data on their customers and operations, but harnessing this data for meaningful insights and actions remains a formidable challenge.
There are three common ways in which companies are activating this data today; manually, within the marketing tools they use, and through CDPs. Each has its merits and drawbacks.
Manual Data Activation
Manual data activation might entail tasks like; downloading a list of event attendees and uploading it to a marketing tool like HubSpot, or cross-checking data within visualisation tools before updating it within their marketing platform.
The cons of this approach are obvious; manual data activation is a time-intensive process, relying on human input introduces the risk of errors, as it is subject to human oversight and potential inaccuracies. For businesses with substantial customer bases, manual processes cannot scale efficiently, as the number of data points to manage becomes overwhelming.
There are pros with doing things manually. It allows for a high level of customisation. This can be beneficial when dealing with a small segment of high-value users, where they really need to feel as if you are speaking to them and just them. It is also ideal for handling unique or unusual cases where the right course of action or communication is not obvious.
Within Existing Tools
Many companies opt to use their existing tools, such as Customer Relationship Management (CRM) and marketing tools like HubSpot or Salesforce, for data activation.
Leveraging existing tools is convenient, as employees are already familiar with their functionalities. It allows for a quick start in data activation without the need to invest in new systems and so long as companies consider data quality and oversight of these tools, then they can act as that single source of truth.
But therein lies the problem. Relying on these tools can magnify data quality issues. Even something as simple as a misclassification of a sales lead could mean substantial time and marketing spend wastage. While these tools often incorporate features like propensity models and lead scoring, it is quite common for them to employ simple, one-size-fits-all model, providing generic insights that may not be specific to a company’s unique needs.
So What Would We Recommend?
When it comes to activating data, there is another route called Reverse ETL. In a normal ETL process data is extracted from its source, loaded into data storage, transformed and combined through modelling into business metrics and then visualised. What reverse ETL does is it takes that modelled data and pipes it into any application. So you might use 4 different data sources to understand which customers are going to churn. Once you have that data modelled, instead of this metric living in a reporting tool, you can send it directly to a CRM for your team to intercept.
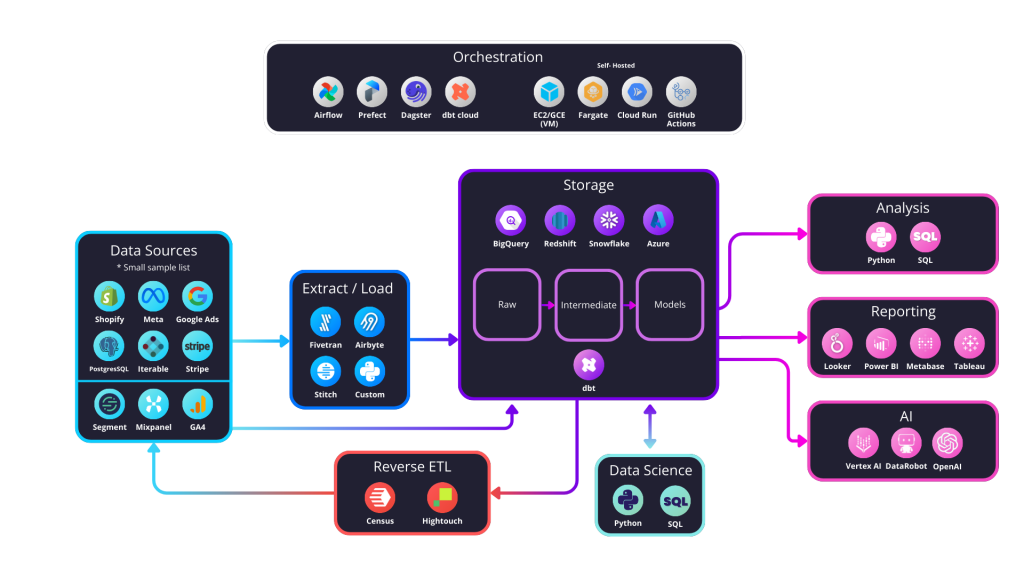
Reverse ETL gives you many of the positives from above, without the downsides namely:
Your modelled data can be used to create lists, flags and notifications inside the applications your teams use and are familiar with, making data activation easier and more effective.
That also means that you can create settings for those customers who should have manual intervention or that personal touch with ease.
Reverse ETL relies on data from within your data warehouse/lakehouse which means it doesn’t create another data silo and ensures that your warehouse is a single source of the truth.
Reverse ETL is today, much more cost effective than a CDP, and tools like Census are easy to set up, but you first need that solid data infrastructure as above.
Want To Get Started?
If you want to create more value from data but are not sure where to start, why not get in touch with a friendly member of the 173tech team today?