


Introducing SAYN
In simple terms, SAYN is an open source data processing framework. We have built it to be the simplest framework whilst maintaining full flexibility. Users can select from multiple predefined task types and build their own ETL processes. SAYN is really unique and unlike anything you have seen before. Want to know more? Then read on!
Modern Analytics: The Context
Before we speak more about SAYN, let’s start with a quick refresher to place things in context. Modern analytics infrastructures are usually organised around a data warehouse using five core layers as shown on the following graph: Then read on!
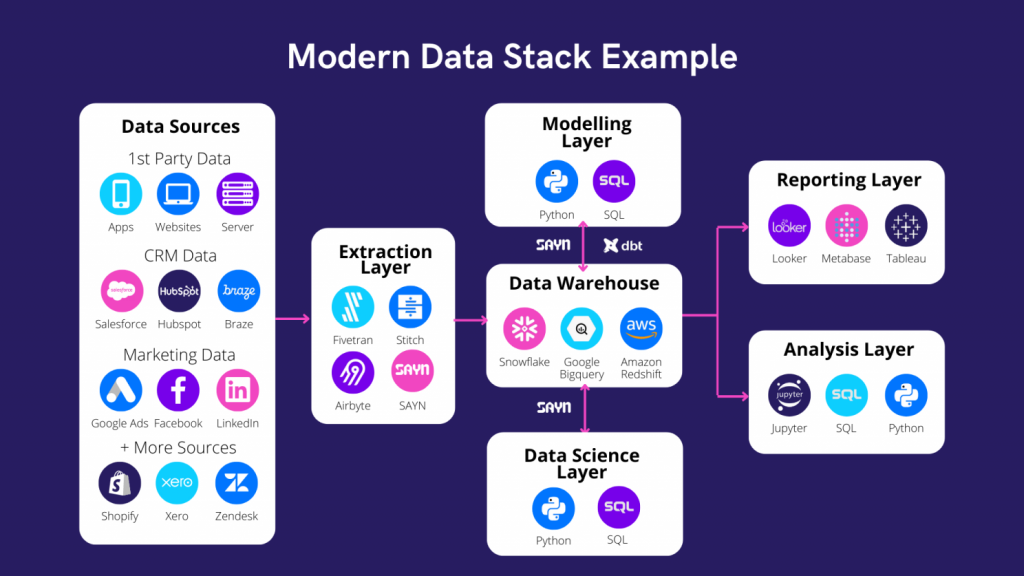
It is crucial to have an efficient and scalable data process in place that can easily support the creation and maintenance of hundreds and more tasks and their dependencies. There are two common ways to go about this:
- Using technical workflow management frameworks such as Airflow which can be quite complex to setup and lead to more maintenance.
- Taking a lightweight approach using tools such as Stitch + DBT which lacks flexibility as it doesn’t provide a flow for Python processes such as custom extracts or data science models.
What if you want to maintain high flexibility in your analytics processes at scale, but also keep things simple? Well, as it turns out, we never found a data processing framework that efficiently addressed those concerns. So we built it!
SAYN: The Genesis
We believe simplicity to be crucial when maintaining pipelines at scale. However, we also believe that simplicity should not come at the expense of flexibility. This is why we have built our own open source data processing framework: SAYN. SAYN is designed to empower analytics teams by being simple, flexible and centralised. It democratises the contribution to data processes within an analytics team, enables full flexibility and helps save a lot of time through automation.
SAYN is built around the concept of tasks and currently has the following task types pre-built for you:
- sql: executes a SQL query against the database.
- autosql: automates the data transformation process. You write a SELECT statement and SAYN takes care of the table/view creation for you. It can also be used for incremental loads.
- python: execute Python code.
- copy: automatically copy data from one database to another.
- and more are to come!
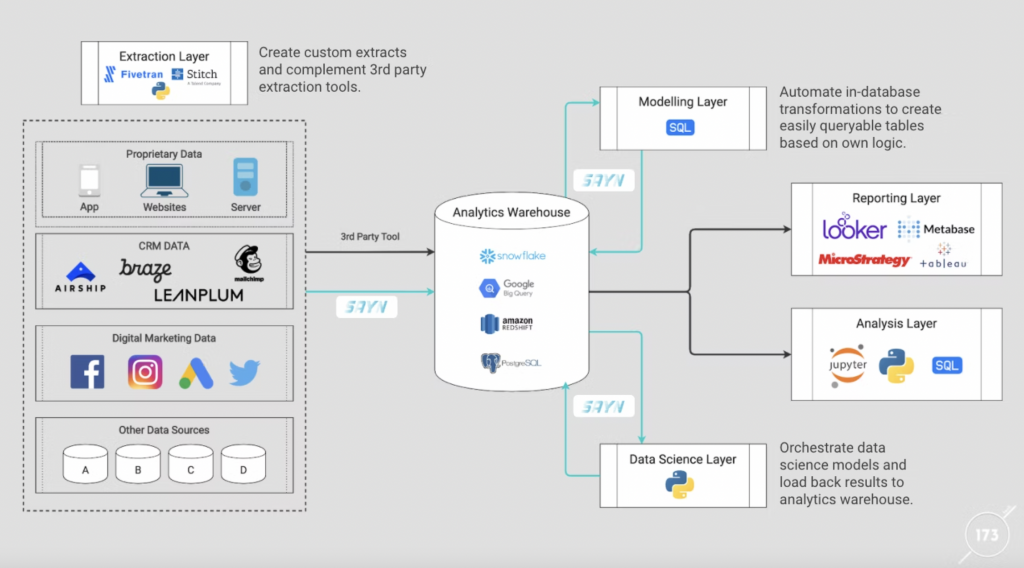
The following graph displays how we typically use SAYN in the modern analytics stack. The blue lines are orchestrated by SAYN:
SAYN Philosophy
SAYN is designed around three core beliefs that a modern data processing framework should empower data engineers and analysts by being simple, flexible and centralised. This is how SAYN lives up to that promise:
Simple
- Project structures and tasks are defined in YAML, a very simple language often used for configuration. This has the significant advantage that every analyst or engineer can easily contribute to the pipeline and add new data processes.
- You can execute any combination of task(s) with the command sayn run including your Python tasks, enabling a smooth and efficient workflow.
- SAYN provides a lot of automation and reduces data engineering complexity through its task types (e.g. turning SELECT statements into tables/views automatically, copy data from one database to another) and its API (e.g. pre-built database connections and credentials selection to access in your Python code). Your team can focus on writing logic code as opposed to pipeline code.
- Tasks can be defined with as little as 2 lines of YAML and the code to execute. You can generally get going with SAYN super quickly!
Flexible
- SAYN enables you to use both SQL and Python, meaning that you can literally do anything on the analytics spectrum: data extraction, modelling and data science.
- SAYN is powered by Jinja, allowing you to easily make your code dynamic. For example to switch between prod and dev environments.
- You can define any database structure you prefer, SAYN does not force you by default into any specific design.
Centralised
- SAYN can be used across the whole pipeline, enabling you to centralise and version control all analytics code in your SAYN project.
- Task definition is centralised in the YAML files which build the backbone of the SAYN orchestration.
How SAYN Works
The best way to see how great SAYN is is to actually try it! SAYN is distributed on PyPi and works using the command line. It is executed using the sayn run command. You can literally get started in 2 minutes with the following four lines:
$ pip install sayn
$ sayn init test_sayn
$ cd test_sayn
$ sayn runThis will install the sayn package, create a SAYN project called test_sayn, move you into the project directory and then execute SAYN. You should see the following happening:

As mentioned before, SAYN projects are organised around the concept of tasks:
- Tasks define your data processes and their relationships, SAYN then builds a Directed Acyclic Graph (DAG) automatically for you.
- SAYN supports multiple task types. You simply define your task by selecting a type, define the required attributes if any, and specify the code to run.
- Tasks can be separated in different YAML files (considered to be “task groups”) to separate the data processes (e.g. core, marketing, data science) and keep your projects organised as you scale.
Here are some example use cases of SAYN:
- In-warehouse automated data transformations using autosql tasks. This is extremely powerful for data modeling processes such as calculating marketing ROI.
- Automatically copying data from an operational database replica to an analytics cluster.
- Using a Python task to complement an extraction tool such as Stitch when extractors are missing or when an extraction is done inefficiently.
- Using a Python task to create a LTV prediction data science model and load results to your data warehouse.
Want To Know More?
We are actively developing SAYN and it is getting even better by the day! SAYN has made our lives so much easier at 173Tech and it really unleashes our analytics proficiency. Your team can benefit from it as well! In addition, we would love to get feedback that can help us make the framework even better so please do reach out, we’re friendly 🙂 You can contact us for questions or suggestions regarding SAYN via sayn@173tech.com. Speak soon!