


Building A Simple ETL With SAYN
In this article, I want to give you a bit more insight into how SAYN works, how we currently use it in ETL / ELT processes and its benefits. In addition, we will go through an example SAYN project mimicking an ETL process and also learn a bit of Yodish (the language of Yoda, this is) along the way!
SAYN: Simplicity & Flexibility In ETL Processes
We created SAYN because we faced the following challenges with existing solutions:
- Lightweight setups (e.g. Stitch + DBT) get you started quickly. However, they lack Python support which can become problematic if you need more than what third party extractors can offer (e.g. missing data source) or if you want to integrate data science models.
- More advanced setups (e.g. Airflow) give you full flexibility but the technical expertise required for setup and maintenance (due to the high number of services required) makes it challenging for teams which are not stacked with many data engineers.
This forged the philosophy that led SAYN’s design: easy to deploy, run and maintain whilst enabling full flexibility in analytics processes. And further translated into the following core features:
- The SAYN directed acyclic graph (DAG) is written in YAML, enabling any member of an analytics team to easily contribute to the pipeline – no matter whether they know Python or not.
- Both the YAML task definitions and task code can be made dynamic through the usage of Jinja templating and parameters.
- All SAYN tasks are executed with the
sayn runcommand. This means that deployment can simply be done with a single cron job on a server (e.g. EC2) or using serverless options (e.g. GCP Cloud Run). As a result, you can deploy SAYN in minutes as you do not need a multitude of services to setup and maintain! - Out-of-the-box SQL transformation tasks so that you can easily plug it on top of a 3rd party extraction tool.
- Python tasks, which means that you can easily and efficiently integrate custom extracts and / or data science models in your workflows when necessary.
- Automatically copy data from a database to your warehouse.
- And there’s more to come!
We have used SAYN on multiple ETLs with over hundreds of tasks and it works like a charm! Because of its features, it enables you to choose the most optimal option when building analytics workflows whilst keeping the overall infrastructure extremely simple to maintain. The following chart displays how we deploy SAYN infrastructures:
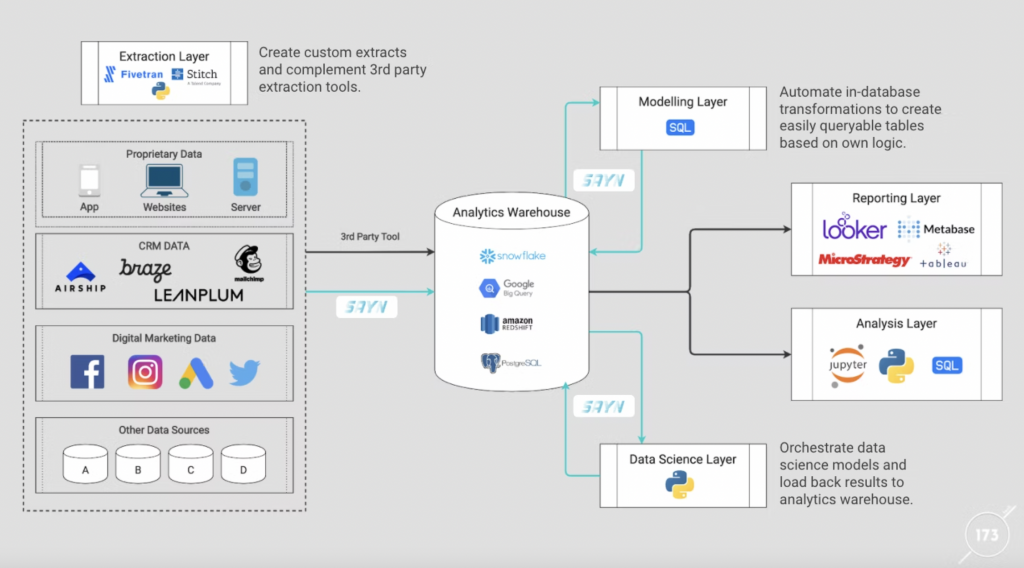
Now that you have a good overview of what SAYN is, let’s go through a very simple ETL built with SAYN so you can get a feeling of how the framework works.
A Simple ETL Using SAYN
We will navigate you through the usage of SAYN with a simple ETL project. You can find the project on github here and download it with the command:
git clone https://github.com/173TECH/sayn_project_example_simple_etl.git
The ETL that this project implements operates the following:
- Collecting jokes from an API and then translating them into Yodish with another API.
- Creating some data models (SQL transformations) on this raw data.
Both APIs are free and do not require an API key so you can run the project directly. However, there are quotas per API (the Yoda translation API limits at 5 calls per hour) so you should avoid running the extract task multiple times per hour. Before running the project, you should:
- Rename the
settings_sample.yamlfile tosettings.yaml. - Install its dependencies (the sayn and requests packages) with
pip install -r requirements.txtfrom the root of the project folder.
Project Structure Overview
A SAYN project is composed of the following components:
project.yaml:defines the SAYN project. It is shared across all collaborators on a project.settings.yaml:defines the individual user’s settings. It is unique for each collaborator and should never be pushed to git as it will contain credentials.tasks:folder where the task files are stored. Each file is considered a task group.python:folder where scripts for python tasks are stored.sql:folder where SQL files for sql and autosql tasks are stored.logs:folder where SAYN logs are written.compile:folder where compiled SQL queries are stored. Before execution, SAYN compiles the SQL queries using Jinja based on the parameter values defined in the project and settings.
For simplicity, we are using a SQLite database for this project. You can use DB Browser for SQLite in order to see the content of the tables created easily.
The project is composed of three tasks:
- Python task for data extraction and load.
- Autosql task to calculate joke statistics.
- Autosql task to compare the lengths of jokes.
You can run the project simply with the command sayn run from the root of the project (more details on all commands available here). When doing so, you should see the following happening:

Data Extraction (Python Task)
The first step in our process is the data extraction and load. This is done by the Python task called extract_jokes_translated.
This task is defined in our base.yaml tasks file as follows:

The code executed by the task is defined in the python/extract_jokes_translated.py file:

Here is how a Python task works with SAYN:
- The task is defined in YAML with the type
pythonand then the class that needs to run is specified. - The class itself is defined in the
extract_jokes_translated.pyfile in the python folder. The class inherits from thesayn.PythonTaskobject. The class should define arunmethod (asetupmethod can also be defined although this is not mandatory). The run and setup (if defined) methods need to return a status:self.success()orself.fail(). - In the task YAML definition, we have defined some parameters which enable us to make the code dynamic; these parameters are used in the setup phase via
self.parameters. - In addition, we also define a
user_prefixparameter on the project. This is first defined inproject.yaml(the default value for the project) and then overwritten in ourdevprofile used by default insettings.yaml. This parameter allows us to avoid table conflicts from multiple project users during testing. Although this is not implemented on this project, parameters can also be used to easily differentiate between dev and production environments (e.g. by assigning different schema values based on the profile used at execution time). - Finally, we control whether or not the task should force a full refresh of the table using the
full_refreshvalue of therun_argumentsattribute from the PythonTask object. This will evaluate to False unless the-fflag is added to the command.
Data Modelling (autosql Task)
The second step in our process is the modelling of the loaded data. This is done through two autosql tasks. These tasks automate the transformation process by turning SELECT statements into tables or views.
f_jokes_stats
This task is defined in base.yaml as follows:

This is the most “verbose” way of defining an autosql task. The next example shows how you can significantly reduce this. The task executes this SQL code:

Here is how an autosql task works with SAYN:
- The task is defined in YAML with the type
autosql. - It needs to specify the following attributes: file_name, materialisation (table, view or incremental) and destination.
- In this example, we leverage the use of the
user_prefixparameter to make the table name dynamic. - We define the parentage relationship of the task. In this case the task is dependent upon the completion of the extract task
extract_jokes_translated. - We also add the tag
modelsto this task so we can execute all models only if desired using thesayn run -t tag:modelscommand. - This task points to the
f_jokes_stats.sqlfile in thesqlfolder.
f_jokes_length_comparison
This task is defined in base.yaml as follows:

For this task. We leverage the preset feature of SAYN which enables us to define multiple tasks which share a similar configuration (the concept is similar to inheritance). The models preset is defined in base.yaml as follows:

Hence, this task will have all the properties of the models preset. We only need to define a parent on the task directly.
Running The Project
You can run the project using the command sayn run. This will create three tables in the SQLite database (one per task):
- The table created by the Python task contains our logs (and the Yodish translations!).
- The table created by the
f_jokes_statstask models the data and adds some statistics about the character length of the joke in each language. - The table created by the
f_jokes_length_comparisongives us the proportion of times when the translated joke is longer than the joke in English, per joke type. It appears that Yodish is generally longer than English! (although this might change based on the data you pull from the random joke API).
Once you have run the project once, use the sayn run -x tag:extract command to avoid re-running the extraction task (as both APIs used have quotas).
Knowing More
That’s all folks! This article gave you a very quick walk through on how a SAYN project works. You can find more details about SAYN in our documentation including:
- The core concepts of SAYN and the details of other available tasks (including the copy task which we did not cover here).
- More fleshed out tutorials which will give you more insight into all the core concepts of SAYN.
If you have any specific questions about SAYN or the project in general, you can reach out to us on hello@173tech.com. Speak soon!