Design a recommendation engine that improves how fractional advisors are matched to startup opportunities.
Obstacle
The existing process produced inconsistent results, and had no data foundation robust enough to support automation at scale.
Outcome
A fully specified MVP architecture, covering data gap analysis, taxonomy design, data collection and migration plan.
Background
Connectd is a platform connecting startups with fractional advisors and NEDs. The matching process, pairing the right advisor to the right opportunity at the right moment, is the core value proposition of the business. But the existing approach was producing results the placement team could not rely on. Connectd knew they needed something better. The question was what, and how to get there without building the wrong thing.
Challenges
Inconsistent Results: The current system was a mix of AI and manual work, but without the solid data foundations needed, as such a number of problems were arising. Advisors who had just started other placements were appearing in recommendations. Candidates with cancelled subscriptions were still surfacing. Industry weighting was inconsistent. Nuanced requirements from discovery calls weren’t being picked up. When it worked, it worked well, but when it did not, the team was wasting time reviewing candidates who were not actually available or relevant.
A Prototype That Could Not Scale: The existing matching process had been built for speed, not durability. Every new listing triggered a mass LLM call across the entire candidate pool, meaning costs scaled linearly with volume, response times were unpredictable, and there was no way to audit, explain, or iterate on why a particular recommendation had been made. There was no feedback loop, no structured way to measure whether matches were actually succeeding, and no separation between the logic that should run once at data ingestion and the logic that should run at query time. As a foundation for a business-critical matching system, it had reached its ceiling.
Solution
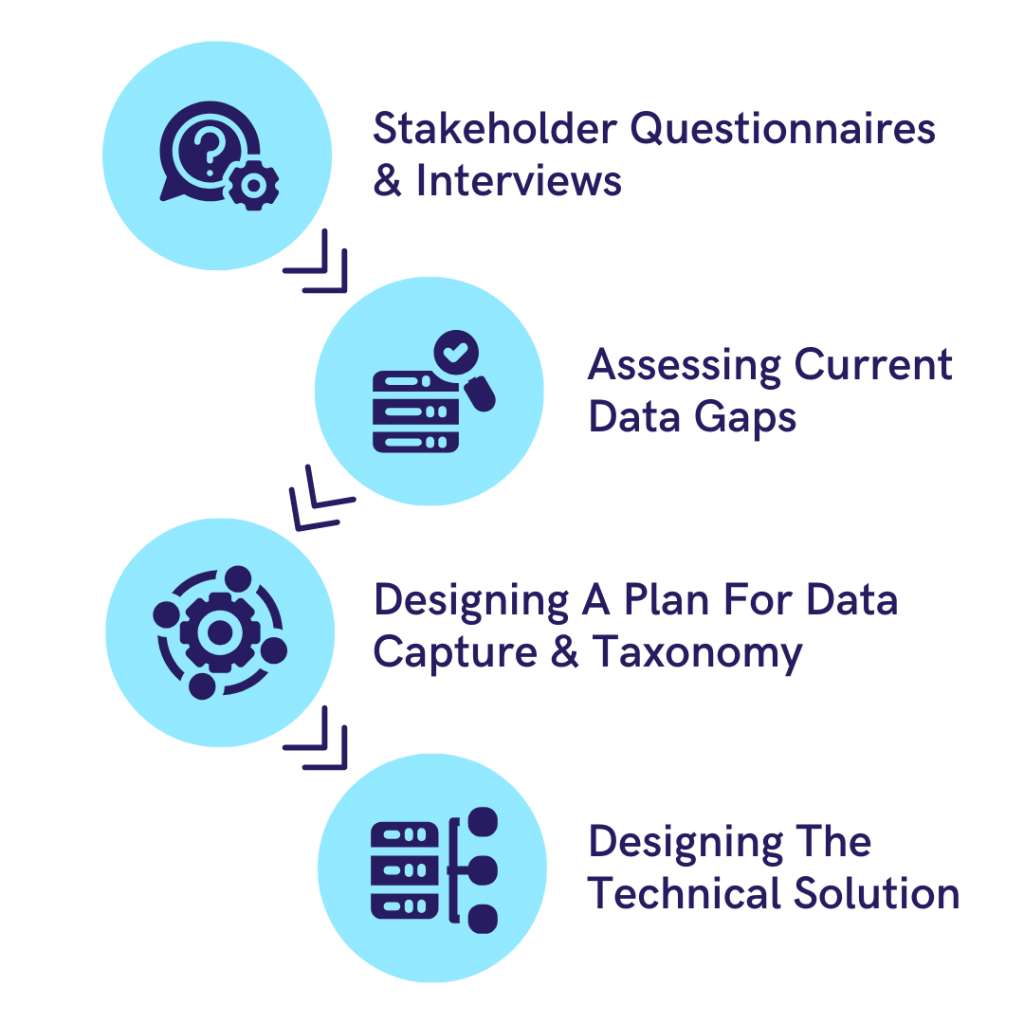
Starting With Questions, Not Assumptions: Rather than jumping straight to a technical solution, 173tech began with a structured discovery process. A detailed questionnaire and stakeholder interviews helped us to understand the business context, the placement workflow, and what the matching process needed to achieve. This qualitative foundation shaped everything that followed.
Building a Taxonomy: One of the most important early outputs was a shared taxonomy; a standardised set of definitions for skills, industries, functions, seniority levels, and role types that would underpin every subsequent stage of the work. Without this, any matching logic would be built on inconsistent foundations: one advisor’s “fintech” is another’s “payments,” and a matching algorithm that cannot resolve those differences will produce unreliable results regardless of how sophisticated the underlying model is.
Data Gaps: With the taxonomy in place, 173tech conducted a full data gap analysis across the four core entities the matching algorithm would need to work with: candidates, business contacts, listings, and placements. The gap analysis didn’t just identify what was missing, it classified each field by priority, proposed whether it should be collected via UI changes, extracted from existing unstructured data using LLMs, or derived as a calculated metric in the modelling layer.
Designing The Solution: Only once the data foundations were fully understood did 173tech turn to the matching architecture itself. The recommendation was a three-stage pipeline designed to be cost-efficient, explainable, and scalable. The first stage normalises and enriches all candidate and founder data at ingestion, the second stage generates a deterministic shortlist using hard pass/fail filters and only at the third stage, applied to the top ten to twenty candidates, does an LLM enter the process to provide qualitative judgement, nuanced ranking, and human-readable rationale for each recommendation. Two implementation paths were specified with trade-offs clearly articulated: a Snowflake-centric batch model extending existing BI infrastructure, and a Postgres event-driven model enabling near-real-time matching at higher operational complexity.
Creating Value For Connectd...
We assessed quality across 115 data fields,
Designed12 shared taxonomies to create a consistent foundation,
And delivered a complete MVP specification — a three-stage matching architecture that replaces an unscalable prototype with a system built to grow.